Before starting to study the generative power of some variants of extended simple eco-grammar systems, we recall the notion of random-context grammars, which is used in the constructions of the chapter.
If the forbidding context is empty for every rule, then we speak about a random-context grammar without appearance checking, otherwise the grammar is with appearance checking.
In the dissertation all random-context grammars are with appearance checking,
so for the sake of brevity sometimes we simply refer to a random-context
grammar with appearance
checking and with ![]() -rules as a random-context grammar.
-rules as a random-context grammar.
We denote the transitive and reflexive closure of
![]() by
by
![]() .
The generated language of a random-context grammar consists of all
the words which can be generated in some steps from axiom
.
The generated language of a random-context grammar consists of all
the words which can be generated in some steps from axiom ![]() .
.
The class of languages which can be generated by random-context grammars
with appearance checking is denoted by
![]() .
It is well known (see [Dassow and PaunDassow and
Paun1989]) that
.
It is well known (see [Dassow and PaunDassow and
Paun1989]) that
![]() , that is,
all recursively enumerable languages can be generated by
random-context grammars with appearance checking and with
, that is,
all recursively enumerable languages can be generated by
random-context grammars with appearance checking and with ![]() -rules.
-rules.
Based on this result, we prove the universality of our models by
simulating random-context grammars with different variants
of simple eco-grammar systems. In these simulations we use another
definition for random-context grammars, so first we show that
the relation
![]() holds for this modified definition, too.
holds for this modified definition, too.
Informally speaking, in a random-context grammar we check the appearance
of the permitting and the forbidding letters and if the result is positive
(there are no forbidding letters in the sentential form and all the
permitting ones are present), we apply the corresponding rule. In
Definition 5.1 this check is done over ![]() ,
that is, the symbol which is about to be
rewritten is left out. In such a way we
can make such a requirement that the letter on the
left-hand side of a rule appears at least twice in the current sentential form
or that the left-hand side appears at most once.
,
that is, the symbol which is about to be
rewritten is left out. In such a way we
can make such a requirement that the letter on the
left-hand side of a rule appears at least twice in the current sentential form
or that the left-hand side appears at most once.
Another possibility is to check the appearance of the symbols in the whole sentential form, this case is presented in the following definition.
The generated language is defined as in Definition 5.2.
Here we denote the transitive and reflexive closure of
![]() by
by
![]() .
.
In the following we present two auxiliary statements which make it
possible to suppose that a random-context grammar has some special
properties. These statements are mentioned in several places
in the literature, for example in [Dassow and PaunDassow and
Paun1989], but without proof.
Therefore we decided to present the proofs here.
The first lemma shows that all the languages which can be generated by random-context grammars working according to Definition 5.1, can also be generated by random-context grammars with complete checking, that is, by random-context grammars working according to Definition 5.3.
In the following, for the sake of simplicity, when a set contains only
one element, ![]() , for the set we use the notation
, for the set we use the notation ![]() instead of the notation
instead of the notation
![]() .
.
PROOF.
We denote by ![]() the number of rules in
the number of rules in ![]() .
The rules of
.
The rules of ![]() are enumerated as
are enumerated as
![]() .
We refer to the components of the
.
We refer to the components of the ![]() th rule as
th rule as ![]() ,
,
![]() ,
,
![]() , and
, and ![]() .
.
Let the components of
![]() be the following:
be the following:
For any,
,

It follows directly from the construction of
![]() that
that
![]() ,
since
,
since
![]() works
according to Definition 5.3 and
works
according to Definition 5.3 and ![]() works according to
Definition 5.1. The main idea is that
if
works according to
Definition 5.1. The main idea is that
if
![]() or
or
![]() holds for a rule of
holds for a rule of ![]() , then we check
the appearance of the symbols in two steps.
The additional symbols
, then we check
the appearance of the symbols in two steps.
The additional symbols
![]() are used to prevent the grammar
are used to prevent the grammar
![]() from starting to simulate a rule of
from starting to simulate a rule of ![]() while another rule of
while another rule of ![]() is being simulated. height 5pt width 5pt depth 0pt
is being simulated. height 5pt width 5pt depth 0pt
Let us note here that the construction of
![]() presented above gives that we can
suppose that
presented above gives that we can
suppose that
![]() ,
,
![]() , and
, and
![]() hold for the rules
hold for the rules
![]() of
of
![]() .
.
By the following lemma, we can suppose that both the permitting and the forbidding contexts of the rules of a random-context grammar with complete checking (that is, working according to Definition 5.3) contain at most one symbol.
PROOF.
As in Lemma 5.5,
we denote by ![]() the number of rules in
the number of rules in ![]() .
The rules of
.
The rules of ![]() are enumerated as
are enumerated as
![]() and we also use the notations
and we also use the notations
![]() , where
, where
![]() and
and
![]() , where
, where
![]() .
We will refer to the components of the
.
We will refer to the components of the ![]() th rule as
th rule as ![]() ,
,
![]() ,
,
![]() ,
, ![]() and to the members of
and to the members of ![]() and
and ![]() as
as ![]() ,
, ![]() ,
,
![]() ,
,
![]() .
.
Let the components of
![]() be the following:
be the following:
,
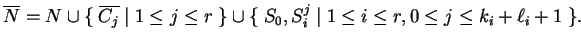
The set
![]() is defined as follows.
For each rule
is defined as follows.
For each rule
![]()
![]() of
of ![]() (
(![]() ,
,
![]() )
we put the following
)
we put the following
![]() rules into
rules into
![]() :
:
All the rules of ![]() can be simulated
by the corresponding
can be simulated
by the corresponding
![]() rules of
rules of
![]() :
first we check the appearance
of symbols in
:
first we check the appearance
of symbols in ![]() , then the non-appearance of symbols in
, then the non-appearance of symbols in ![]() .
Thus
.
Thus
![]() . On the other
hand, it follows from the construction that
the rules of
. On the other
hand, it follows from the construction that
the rules of
![]() which correspond to the same rule of
which correspond to the same rule of ![]() ,
must be used together, one after the other,
in the same order as explained above.
The forbidding context of the second rule prevents the grammar
,
must be used together, one after the other,
in the same order as explained above.
The forbidding context of the second rule prevents the grammar
![]() from starting
the simulation of the same rule more than once. Two different rules cannot be
simulated at the same time because only one symbol
from starting
the simulation of the same rule more than once. Two different rules cannot be
simulated at the same time because only one symbol ![]() is in the sentential
form and its index determines the rule to be simulated.
This gives
is in the sentential
form and its index determines the rule to be simulated.
This gives
![]() . height 5pt width 5pt depth 0pt
. height 5pt width 5pt depth 0pt
We note here, that like in Lemma 5.5,
![]() ,
,
![]() , and
, and
![]() hold for the rules
hold for the rules
![]() of
of
![]() .
.
The two lemmas together with the result
![]() gives that
any recursively enumerable language can be generated by a
random-context grammar which uses complete checking and whose permitting and
forbidding contexts contain at most one symbol.
gives that
any recursively enumerable language can be generated by a
random-context grammar which uses complete checking and whose permitting and
forbidding contexts contain at most one symbol.